

Data Engineering Services: Why AI Readiness Starts With Your Data Infrastructure
Last Updated on: June 5, 2026

Key Takeaways
I. Why data engineering is now an AI prerequisite
II. What data engineering services cover
III. Five architecture decisions that determine AI outcomes
IV. What to demand from data engineering service providers
V. Why Systango for data engineering and analytics
Enterprises are spending more on AI than ever before. Yet the majority of AI initiatives in production today underperform against their original business case.
The reason is rarely the model. The model is fine. What fails is the infrastructure underneath it. Inconsistent pipelines, siloed data estates, and schemas built for reporting rather than training mean that even the most capable foundation models produce unreliable outputs.
Data engineering services have become the most consequential – and most underestimated – component of any AI or analytics programme. This guide covers what they are, why they determine AI outcomes, and what separates data infrastructure that compounds in value from data infrastructure that creates debt.
I. Why data engineering is now an AI prerequisite
Most AI failure is a data problem. Teams invest months selecting frameworks, fine-tuning models, and building inference pipelines – then hit the same wall: the data feeding those systems is incomplete, inconsistent, or structured for a different purpose entirely.
A language model trained on poorly governed data hallucinates at a higher rate. A fraud detection system built on siloed transaction data misses patterns that only emerge when streams are joined. A recommendation engine trained on incomplete history recommends poorly – and confidently.
Data analytics consulting engagements consistently surface the same root cause: organisations built their AI and analytics layers before they built the foundation. The result is technical debt that compounds with every new data source, every new model, and every new compliance requirement. AI readiness is an engineering problem first.

II. What data engineering services cover
1. Data architecture and pipeline engineering
- The foundation is architecture – a deliberate design for how data moves from source systems into analytical and operational environments.
- ETL/ELT pipelines, real-time streaming infrastructure (Apache Kafka, AWS Kinesis, Google Pub/Sub), and change data capture patterns keep downstream systems synchronised without brittle point-to-point integrations.
- For AI workloads, pipeline reliability is non-negotiable: a model served by an unstable pipeline degrades silently.
2. Data modernisation: warehouses, lakes, and lakehouses
- Data modernisation services typically migrate from legacy on-premise warehouses to cloud-native platforms – Redshift, BigQuery, Databricks, Snowflake – structured around a lakehouse architecture: the governance and query performance of a warehouse with the flexibility of a lake.
- For AI teams, this matters because feature engineering requires joining structured transactional data with unstructured sources – logs, documents, sensor feeds, behavioural events. A lakehouse makes that possible without expensive workarounds.
3. Data modelling for AI workloads
- Standard dimensional modelling serves BI well. AI workloads require more – feature stores, embedding stores, and semantic layers that make data queryable by both humans and models.
- Data engineering consulting services that lack ML engineering context default to designing for dashboards.
- The delta between a data estate optimised for reporting and one optimised for AI is significant and expensive to close later.
4. Business intelligence and analytics
- Data analytics services convert governed, structured data into decisions – dashboards, KPI frameworks, self-service analytics, and operational reporting.
- The quality ceiling of any BI implementation is set entirely by the data engineering beneath it. Best-in-class visualisation on top of poorly modelled data produces confident, wrong decisions.
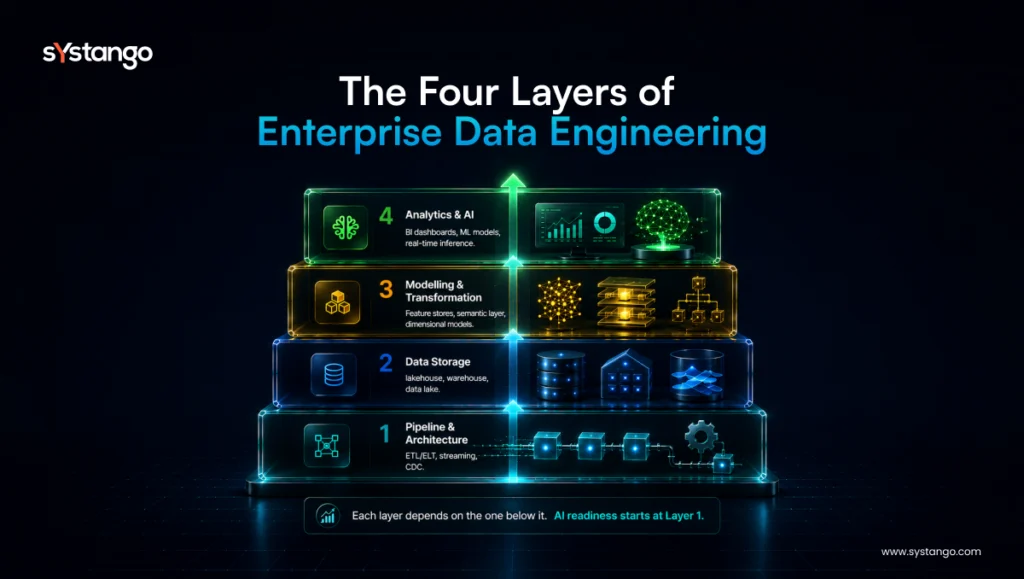
III. Five architecture decisions that determine AI outcomes
Most data engineering service providers can build a pipeline. Fewer make the upstream architectural decisions that determine whether that pipeline supports AI at scale:
- Real-time vs batch: AI applications increasingly require real-time feature serving – fraud scores at transaction time, personalisation at page load. Batch pipelines cannot serve these. The decision must be made before build.
- Schema-on-read vs schema-on-write: The choice directly affects how quickly data scientists can access new sources and how reliably ML pipelines can consume them.
- Data contracts: Organisations with mature data analytics consulting practices implement data contracts – formal agreements between producers and consumers enforcing schema, freshness, and volume expectations automatically.
- Feature store architecture: Without a centralised feature store, the same features are recomputed independently by multiple teams, creating training-serving skew – one of the most common causes of silent model degradation.
- Governance and lineage by default: Regulatory environments – GDPR, DORA, FCA, HIPAA – require demonstrable data lineage and access control. Data modernisation services that embed governance from day one cost significantly less than retrofitting it.
IV. What to demand from data engineering service providers
Cloud certifications matter – but verify active delivery credentials across AWS, GCP, and Azure, not logo placement. Beyond certifications, the questions that matter:
- Does the provider design for AI workloads natively, or default to BI-first architecture?
- Is governance and lineage embedded by default, or an optional add-on?
- Do they take end-to-end ownership from ingestion to insight, or hand off at the pipeline boundary?
- Can they demonstrate ISO 27001 certification and compliance delivery experience?
- Do their case studies cite specific outcomes – not just technologies used?
The best data engineering consulting services engagements are not scoped as infrastructure projects. They are scoped as capability builds – with the explicit goal of making your data estate a compounding asset, not a managed liability.
V. Why Systango for data engineering and analytics
Systango’s data analytics services follow a structured five-phase delivery framework: Discover & Assess, Design & Build, Validate & Optimise, Deploy & Enable, and Scale & Evolve. Each phase is designed to reduce risk, accelerate time-to-value, and ensure what gets built is production-grade and maintainable.
As a cloud-native engineering partner with active specialisations on AWS and Google Cloud – ISO 27001 and ISO 9001 certified, AWS Advanced Partner, and top 20 globally for Google’s Generative AI Services Specialisation – Systango delivers data modernisation services for growth-stage and enterprise organisations across FinTech, InsurTech, WealthTech, and regulated industries globally.
Explore our Data Platform & Analytics services to understand how we approach your specific data engineering services challenge.



